Running massive language models locally usually means choosing between speed and quality, or spending thousands on GPU clusters. Flash-MoE breaks that trade-off by streaming a 397 billion parameter model directly from your MacBook’s SSD at 4+ tokens per second with production-quality output including reliable tool calling. The entire system fits in 48GB RAM while the 209GB model lives on disk.
This isn’t just another inference wrapper - it’s a from-scratch Metal compute pipeline with hand-optimized shaders for 4-bit dequantization, fused multiply-add kernels, and expert streaming that trusts the OS page cache instead of fighting it. The FMA-optimized dequant kernel alone delivers 12% speedup by rearranging math to use GPU fused multiply-add units efficiently. Every bottleneck from SSD bandwidth to GPU utilization has been profiled and optimized.
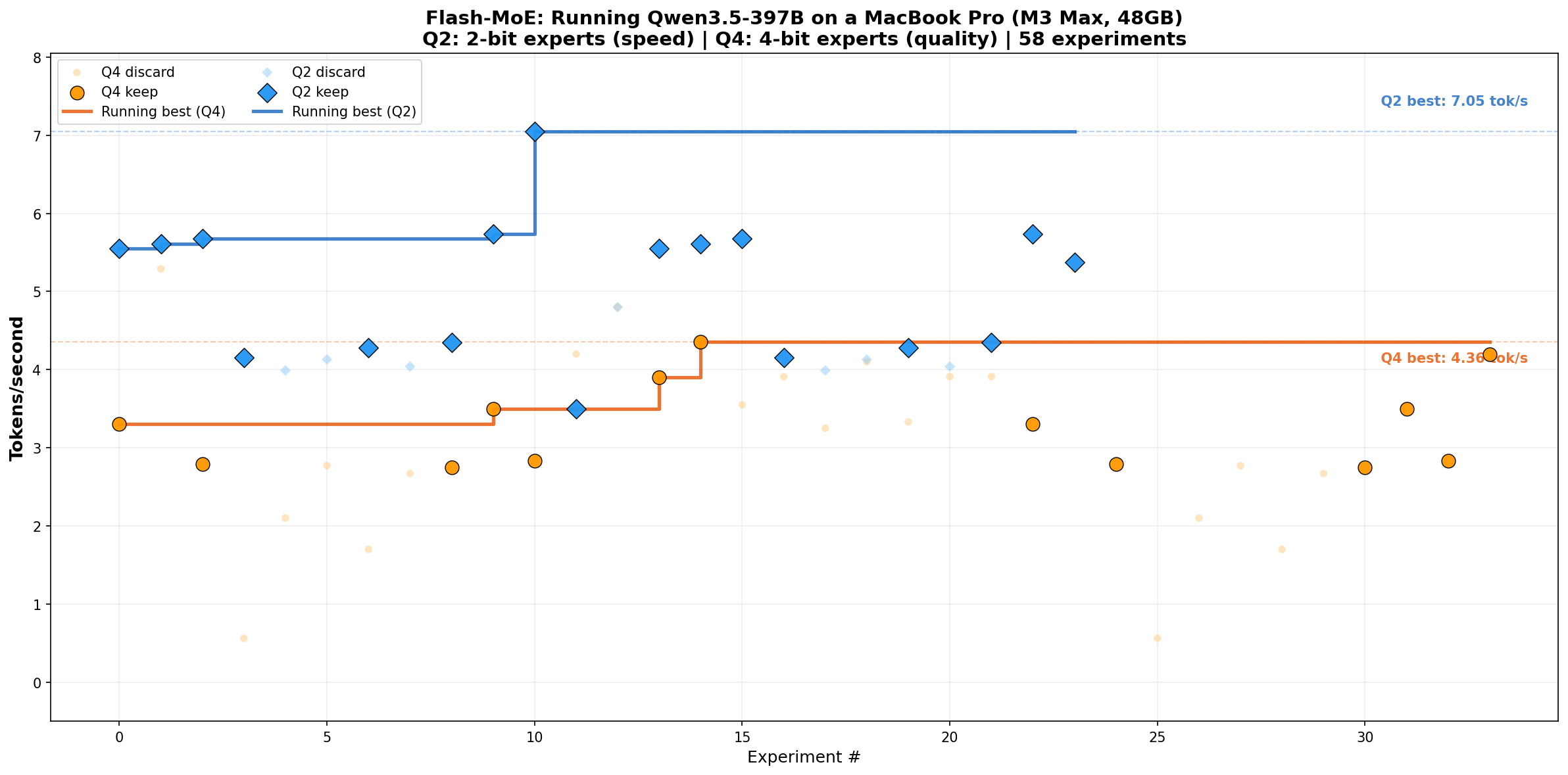
If you’ve been waiting for truly local AI that doesn’t compromise on model size or quality, this 1500-star repo shows it’s possible today. The codebase is pure C/Objective-C with detailed performance breakdowns, and the accompanying paper documents 90+ experiments. Perfect for researchers pushing inference boundaries or developers who want to understand what optimal Metal compute actually looks like.
⭐ Stars: 1521
💻 Language: Objective-C
🔗 Repository: danveloper/flash-moe