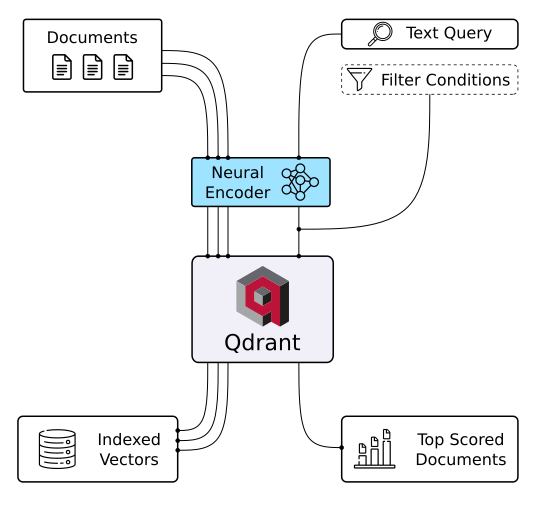
Every AI application eventually hits the same wall: how do you search through millions of embeddings without your users abandoning ship? Qdrant solves this with a vector database built in Rust that’s designed for production workloads from day one. While other solutions choke under real-world traffic, Qdrant maintains sub-millisecond search times even with billions of vectors.
What sets it apart is the filtering system - you can combine semantic similarity with traditional filters (think “find similar products under $50 in electronics”) without the performance nightmare. The HNSW algorithm implementation is genuinely impressive, and being written in Rust means it won’t mysteriously crash when your recommendation engine goes viral. Plus it supports everything from image search to chatbot memory with the same consistent API.
With 29k+ stars and integrations across the ML ecosystem, this isn’t experimental tech - it’s what companies like yours are already using in production. The Python client lets you prototype locally in minutes, then scale to their managed cloud when you’re ready. If you’re building anything with embeddings, this deserves a spot in your architecture.
⭐ Stars: 29027
💻 Language: Rust
🔗 Repository: qdrant/qdrant