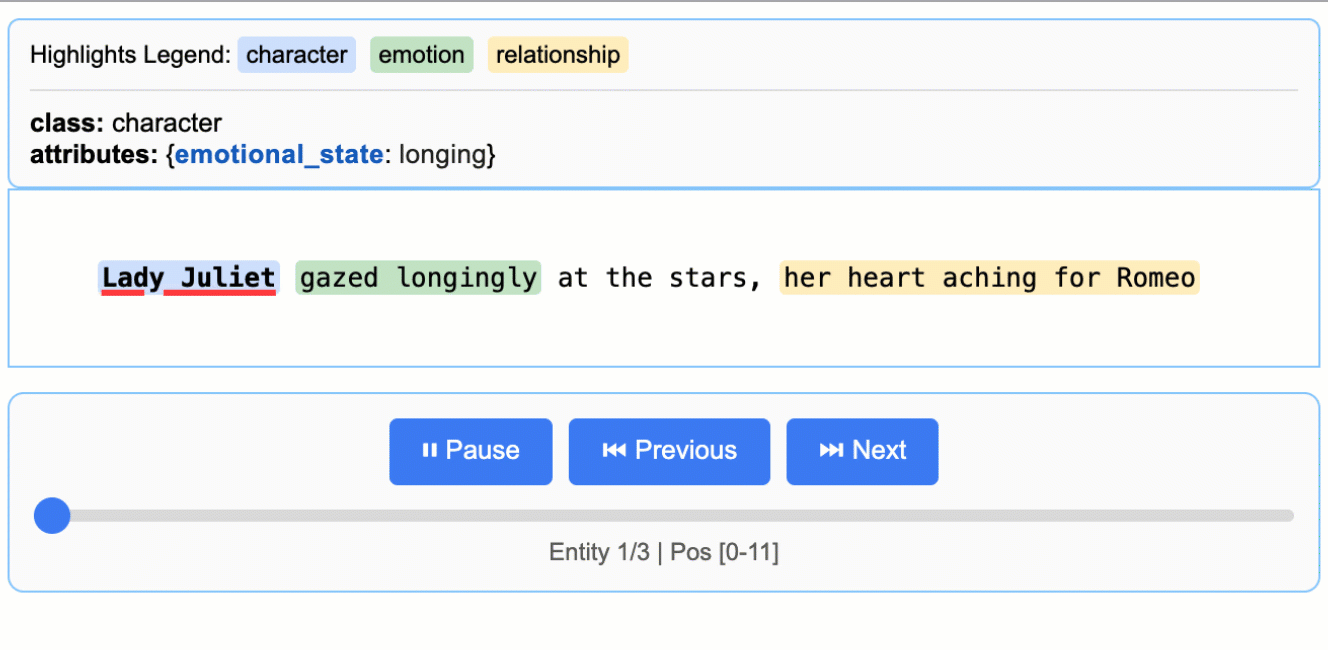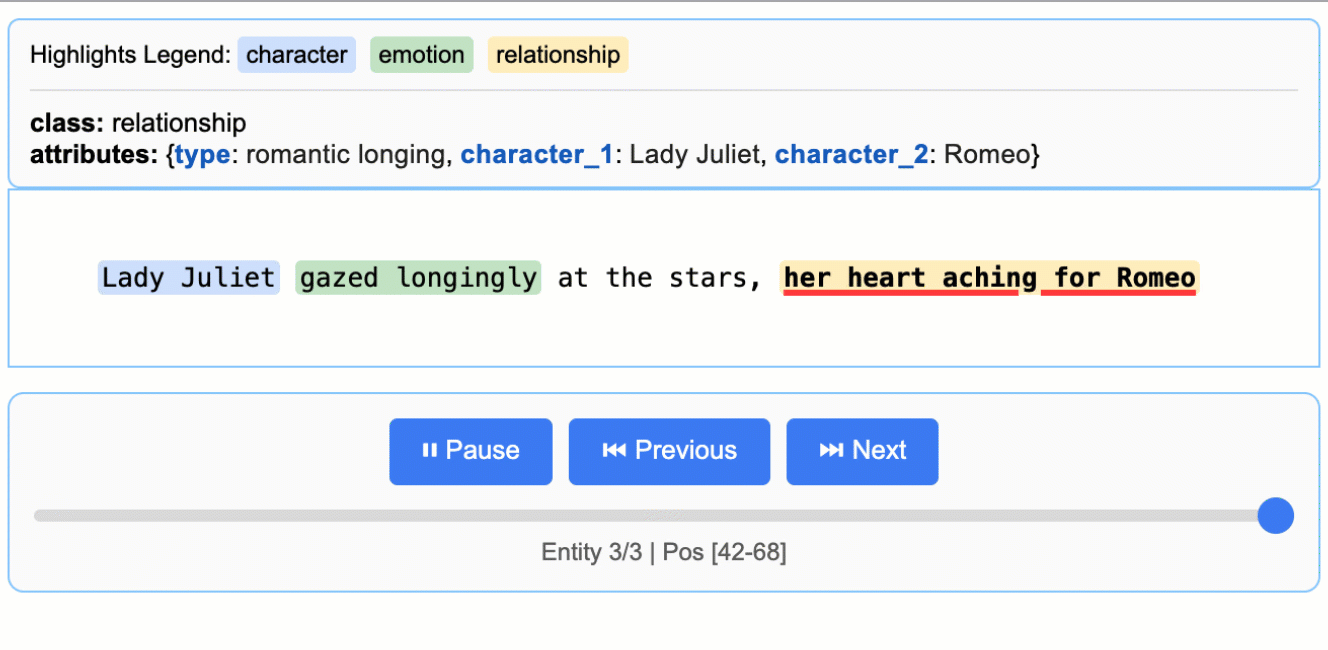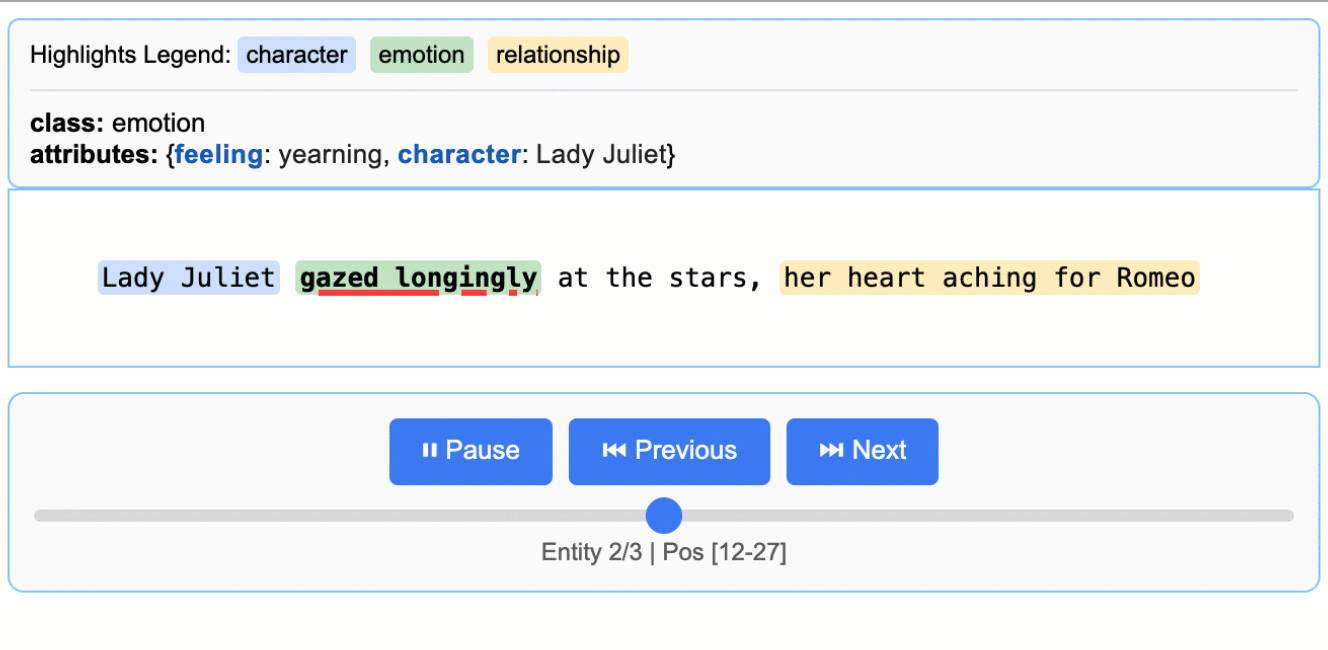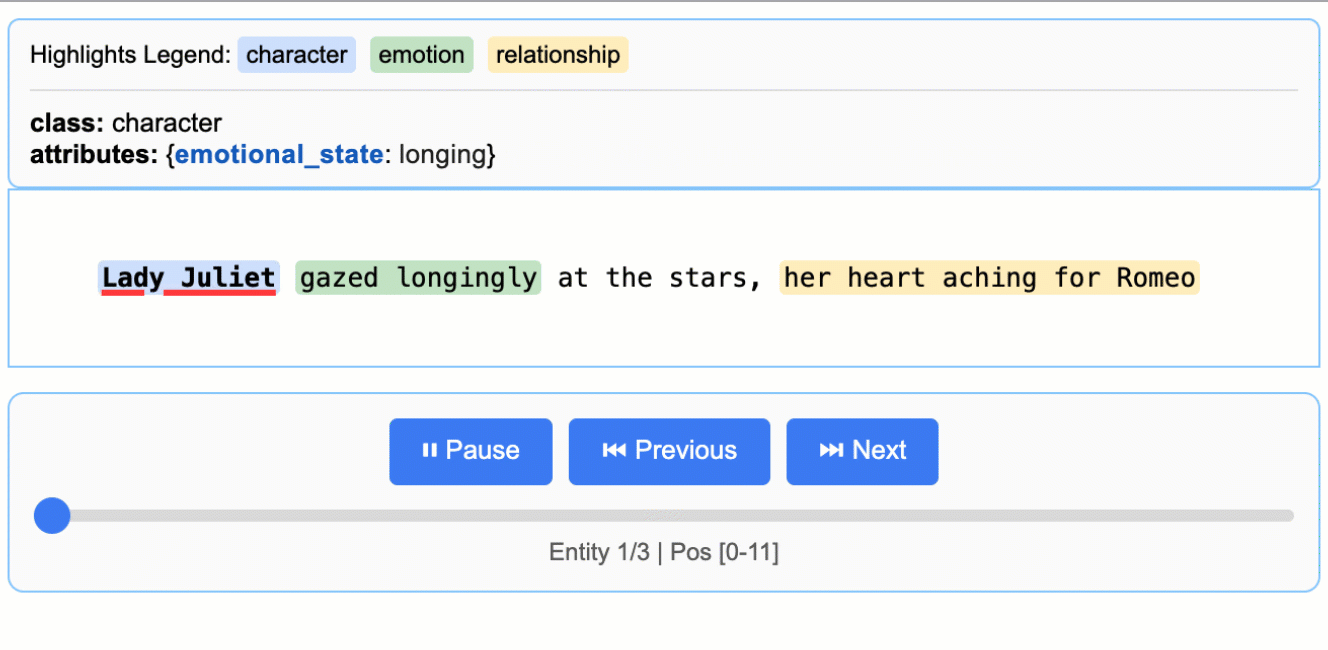
Ever tried extracting structured data from messy documents like medical reports or legal contracts? LangExtract solves the classic ‘needle in a haystack’ problem by not just finding the information you need, but showing you exactly where it came from in the original text. With 25k+ stars, this Google-backed library has clearly hit a nerve in the developer community.
What sets it apart is the source grounding feature - every extracted piece of data gets mapped to its exact location in the source document, complete with interactive HTML visualizations for verification. It handles long documents through smart chunking and parallel processing, supports everything from Gemini to local Ollama models, and adapts to any domain with just a few examples. No fine-tuning required.
Perfect for developers working with clinical notes, research papers, contracts, or any domain where you need to extract structured insights while maintaining audit trails. The few-shot learning approach means you can get started immediately without training custom models, and the interactive visualizations make it easy to validate results with domain experts.
⭐ Stars: 24929
💻 Language: Python
🔗 Repository: google/langextract