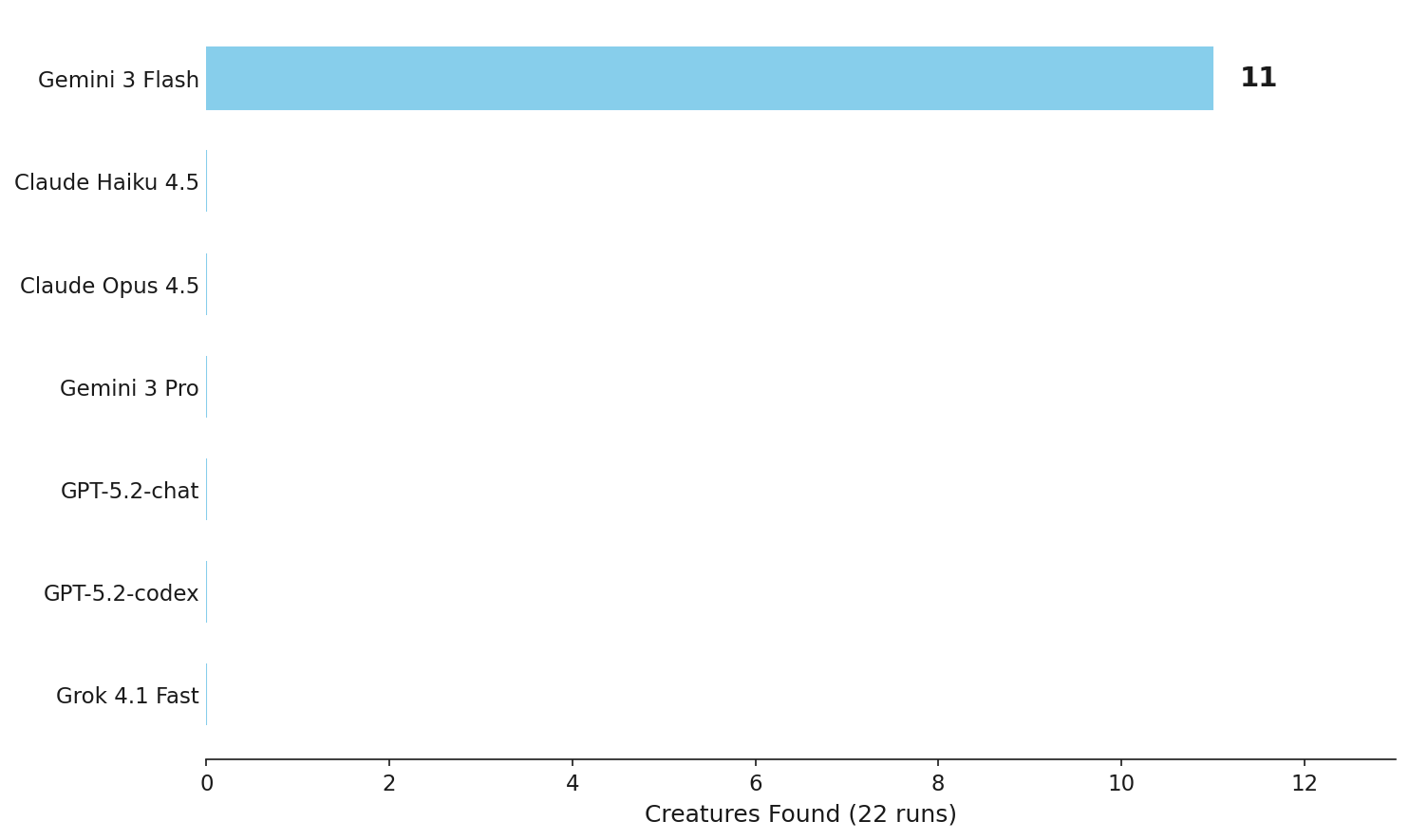
Ever wondered if GPT-4 could actually pilot a drone? SnapBench puts vision-language models to the test with a deceptively simple task: fly a drone through a procedural 3D world and identify 3 creatures. The results are eye-opening – out of 7 frontier LLMs tested, only Gemini Flash succeeded. The killer insight? It wasn’t about intelligence, it was about altitude control. Most models could navigate horizontally but never figured out they needed to descend to ground level where the creatures actually live.
Built with a slick multi-language architecture (Zig simulation, Rust orchestration, Python glue), SnapBench exposes a fascinating gap in spatial reasoning that traditional benchmarks miss. The 3D voxel world generates procedural terrain with cats, dogs, pigs, and sheep scattered around. Models get 8 movement commands plus identify/screenshot, with UDP communication keeping everything snappy. It’s not a rigorous academic benchmark, but it reveals something important: current LLMs struggle with basic 3D spatial tasks that seem trivial to humans. Perfect for researchers exploring embodied AI or anyone curious about the real-world limits of vision-language models.
⭐ Stars: 154
💻 Language: Zig
🔗 Repository: kxzk/snapbench