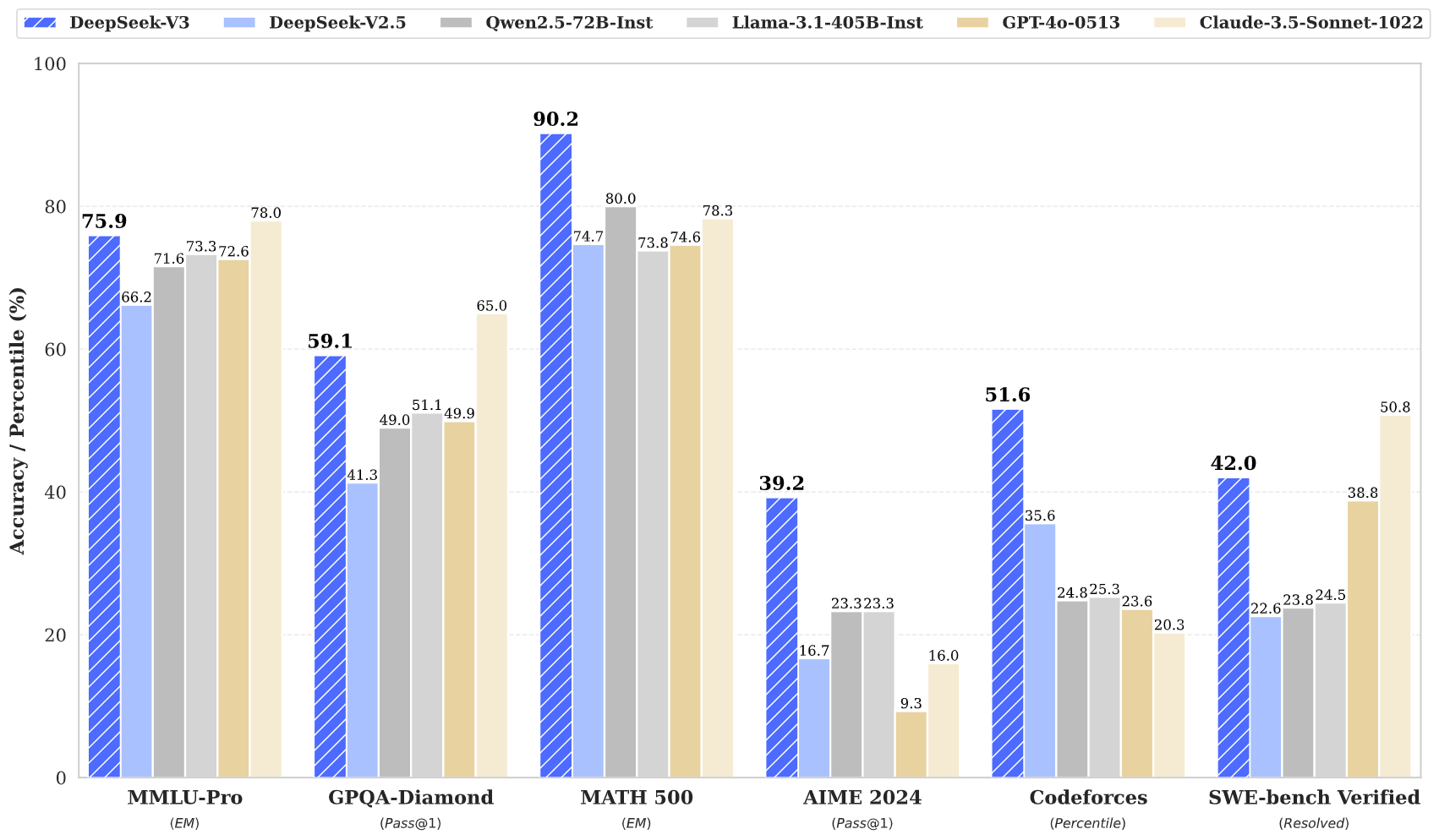
Imagine having access to a massive 671 billion parameter language model that’s smart enough to only wake up the parts of its brain it actually needs. That’s DeepSeek-V3 in a nutshell - a Mixture-of-Experts architecture that activates just 37 billion parameters per token, making it lightning-fast while maintaining the intelligence of a much larger model. With over 834K downloads and 4K+ likes, developers are clearly excited about what this efficiency-first approach brings to the table.
What makes DeepSeek-V3 fascinating isn’t just its size, but how it thinks. The MoE architecture means it can specialize different expert networks for different types of problems - like having a team of specialists who each jump in when their expertise is needed, rather than everyone shouting at once. This translates to better performance per compute dollar and faster inference times, solving one of the biggest headaches in deploying large language models: the crushing computational costs.
Whether you’re building conversational AI, need serious text generation capabilities, or want to experiment with cutting-edge architecture without breaking the bank on inference costs, DeepSeek-V3 offers a compelling middle ground. It’s particularly appealing for developers who need GPT-level capabilities but with more predictable, efficient resource usage.
❤️ Likes: 4017
📥 Downloads: 834,612
🤗 Model: deepseek-ai/DeepSeek-V3